
![]() Today, Qumulo, a scale-out NAS vendor, announced a major new version of their operating environment, Qumulo Core 2.0, and three new hardware models.
Today, Qumulo, a scale-out NAS vendor, announced a major new version of their operating environment, Qumulo Core 2.0, and three new hardware models.
Qumulo is hybrid storage, meaning each node has both Flash and spinning disks. The Flash layer (in this case SSDs) is used for performance and the HDD layer for capacity. Data is moved between these two tiers automatically without end-user action or even awareness.
I’ve written about Qumulo before: I was there at their launch party when they emerged from stealth, and, more recently, I wrote about their new high-density node. I was also directly involved in my company’s first sale of a Qumulo cluster — while the company was still in stealth mode.
I mention this partly to get the “yes, I’m a fan” out of the way early, and partly to give some weight to this statement: this is (in my debatably humble opinion) their best announcement to date.
Qumulo Core 2.0
Qumulo has been working in a agile development mode since they emerged from stealth. This has meant a lot of small, incremental functionality updates have been coming out regularly. This is the first “major” update they’ve had. Version 2.0 of Qumulo Core adds two big new features: erasure coding and capacity trend analytics.
Erasure Coding
I’ve always thought that Erasure Coding was one of the best data technologies out there — but also one of the worst-named… When introduced to the term for the first time, almost everyone has the same reaction, namely: “Why would I want something that erases my data?”
The short version is that erasure coding is a way of writing data by splitting it into multiple parts. These parts are organized in such a fashion that only a subset of the parts is required to recover the original data.
If you’re interested in some of the mathematical ideas involved, Wikipedia has a great article on erasure coding. Qumulo Core 2.0 uses a specific method of erasure coding referred to as Reed-Solomon error correction, named after the two men who developed the initial algorithms in 1960. Outside of RAID 5 or 6, Reed-Solomon is probably the most commonly-used method of erasure coding today. (Yes, non-mirroring RAID is erasure coding, just a specific case of it. (That may be a topic for another post.))
Prior to Qumulo Core 2.0, all data protection on Qumulo storage nodes was done by mirroring the disks (RAID 10 (well, technically RAID 1+0, but no one really calls it that any more)). While effective, mirroring is expensive in terms of usable space. With mirroring, the best you can get for usable capacity is 50% (or less) of your raw capacity.
Qumulo Core 2.0 allows a cluster to withstand the loss of up to two disk drives in a node or a single node within the cluster — without any loss of data. It allows customers to get up to 33% more usable capacity out of their Qumulo nodes.
Qumulo’s 1U nodes have approximately 47.5% of their raw capacity usable when using data mirroring. With erasure coding, approximately 60% of the raw capacity is now usable. For Qumulo’s 4U nodes, approximately 49% of their raw capacity is usable under data mirroring. With erasure coding, approximately 65.4% of the raw capacity is usable.
Capacity Trend Analytics
One of the innovations in Qumulo Core is the near-real-time analytics it offers on what’s happening in the array. Qumulo Core 2.0 adds historical trending and predictive analytics to this, allowing customers to do data management and capacity planning at scale.
Capacity trending is a Software as a Service (SaaS) offering that uses the Qumulo Support cloud. By default, it offers built-in reports on data trending over the past 72 hours, 30 days, and 52 weeks.
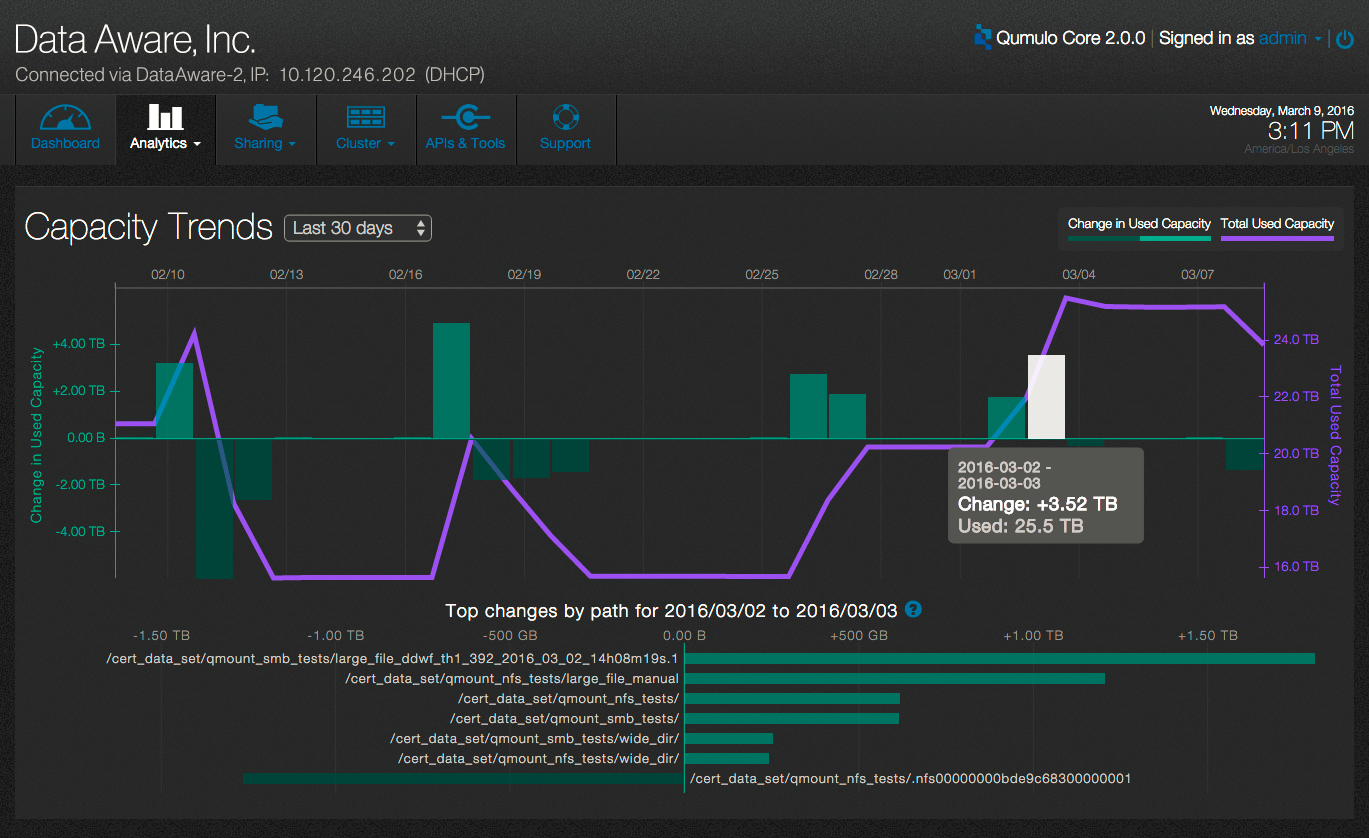
These features allow an administrator a quick and easy way to answer that eternal question: “Wait, what happened to all our free space?” Qumulo Core 2.0’s capacity trend reports can show exactly when capacity changed, in which directories, and who was responsible.
The screenshot below shows an example of a 30-day capacity trending report. (Click on the image to see a larger version.)
New Hardware Nodes
In addition to Qumulo Core 2.0, Qumulo also announced the addition of 3 new models in their QC series of storage appliances.
The first new model, the QC40, adds to their line of 1U storage nodes and offers 40TB of raw storage capacity per node. The specs for Qumulo’s 1U nodes are in the table below.

The other two new models, the QC104 and QC260, are 4U nodes. They offer 104TB and 260TB of raw capacity, respectively. The specs for Qumulo’s 4U nodes are shown in the table below.

You’ve probably noticed that two of the three new models are using 10TB HDDs. These are, in fact, the HGST 10TB UltraStar He10 drives. This gives Qumulo the distinction of being the first storage vendor to market with these high-capacity, helium-filled drives.
Availability
The Qumulo Core 2.0 software is available now.
The new QC hardware nodes will be available before the end of Q2.
GeekFluent’s Thoughts
On the release of erasure coding, I’ll say this: it’s about time. This particular feature is one of the three most-demanded features that Qumulo didn’t have prior to Qumulo Core 2.0. The other two in-demand features that I’m hoping Qumulo will bring into Production ASAP are snapshots and remote replication. I have a lot of customers who could put Qumulo clusters to good use, but require those features for their specific use cases.
I love the addition of the trend reporting and predictive modeling to Qumulo’s analytics. Qumulo bills themselves as creating a “data-aware” storage system and these new features really add to that claim.
I had a conversation with a Qumulo employee recently about their hardware naming scheme. It’s pretty easy to see where the model numbers come from — the model number is simply the amount of addressable raw storage capacity. Personally, I’d always thought the “QC” referred to “Qumulo Core”, but I have learned that this is incorrect. The “Q” does stand for Qumulo, but the second letter refers to the node’s particular role. In this case, “C” stands for “capacity”. This leads me to speculate that in the future we might see a “QP” line of nodes designed for high performance, and perhaps a couple other types of nodes might be on the horizon.
Overall, I remain a Qumulo fan.