![]() Today, PernixData announced version 2.5 of their FVP software product. This product can provide huge storage performance benefits in VMware environments. Since it’s not something I’ve written about before, and it seems that not everyone has heard of PernixData and FVP yet, I’ll spend a little while explaining what it is and why it’s so interesting before I talk about what’s included in the new version.
Today, PernixData announced version 2.5 of their FVP software product. This product can provide huge storage performance benefits in VMware environments. Since it’s not something I’ve written about before, and it seems that not everyone has heard of PernixData and FVP yet, I’ll spend a little while explaining what it is and why it’s so interesting before I talk about what’s included in the new version.
What Is FVP?
FVP is software that enables the use of host-side Flash (and RAM) as a storage performance accelerator. (I know most people would have said “server-side”, not “host-side” there, but I find the word “server” gets confusing in a virtual environment (since people want to run virtual servers), so I will use the word “host” to refer to the physical server hardware.)
Using the FVP software allows for the ability to scale storage performance independently of storage capacity.
FVP was built specifically for VMware environments — in fact it gets installed in, and works at, the hypervisor layer. Support for other hypervisors is on PernixData’s roadmap, but — for the moment — VMware is the only option.
FVP can work to accelerate performance of any VMware-supported storage. This includes:
- NFS
- iSCSI
- FC
- FCoE
- Local host-side datastores
How Does FVP Work?
FVP takes host-side Flash throughout the VMware cluster and virtualizes it into a pool of resources for accelerating writes. Read acceleration happens almost as a side-effect, since data will be served from Flash on a cache hit. The Flash can be either PCIe Flash installed in the host(s) or SSDs installed in the host(s).
In configuring FVP, you create an FVP Cluster. Similar to how a DRS cluster might not contain all of the hosts in the VMware cluster, an FVP Cluster could only contain some of the hosts in a cluster. Those hosts need to have local host-side Flash installed, and only VMs running on those hosts will be able to receive the performance benefits of FVP.
Different hosts in the FVP Cluster may have different amounts and types of Flash installed. FVP has no problem with that.
Whether or not to apply FVP acceleration can be configured on a per-datastore basis. All VMs on the chosen datastore will be accelerated. Customers also have the option of applying per-VM settings, with will override settings inherited from the datastore, allowing customers complete freedom to pick exactly which VMs receive the performance boost.
There are four key features to FVP storage acceleration:
- Fault-Tolerant Write Protection
- Distributed Fault-Tolerant Memory (DFTM)
- User-Definable Fault Domains
- Adaptive Network Compression
Fault-Tolerant Write Protection
In order to ensure that data is protected, it may not be enough to write the data to local Flash before acknowledging the write back to the VM. If the host were to crash immediately following the write to Flash, before the data can be de-staged to shared disk, that data would be unavailable to the VM when VMware HA restarts it on another host in the cluster.
To address this issue, FVP can be configured to create 0, 1, or 2 replicas of all data written. If 0 replicas are chosen, the data is unprotected in the failure scenario above. If 1 replica is chosen, FVP provides fault-tolerance by replicating the new data to Flash on another host in the cluster before acknowledging the write to the VM. If 2 replicas are chosen, FVP provides even more protection by replicating the data to Flash on two other hosts in the cluster before acknowledging the write to the VM.
How replicas are handled is also set on a per-datastore basis, but again, per-VM settings will override the ones inherited from the datastore, again offering full freedom of choice.
Distributed Fault-Tolerant Memory (DFTM)
When I first heard of DFTM, I didn’t understand why PernixData needed two different names for the Fault-Tolerant Write Acceleration (FTWA) feature described above. Once I understood the details, though, it became clear that this is a separate feature.
FTWA uses Flash for storage acceleration. Flash is still really another storage tier, even PCIe Flash (which is a really fast storage tier), but storage — even really fast storage — is still not quite as fast as memory.
DFTM allows FVP to use a portion of host-side RAM for write acceleration (very seriously accelerated writes). Because FVP is working in the hypervisor layer, it has less overhead than other RAM-based solutions. When configuring the FVP Cluster, you can choose how much RAM each host will assign for FVP to use. It does’t need to be the same amount on each host in the FVP cluster.
Again, DFTM can be configured on a per-VM basis by using a combination of the per-datastore and per-VM settings.
User-Definable Fault Domains
This feature is very cool. It allows VMware admins complete control over how they’ll protect the accelerated writes from hardware failures.
This feature allows for the creation of fault domains within the FVP cluster. Writes will be mirrored to Flash in other hosts only if that host is in the specified domain.
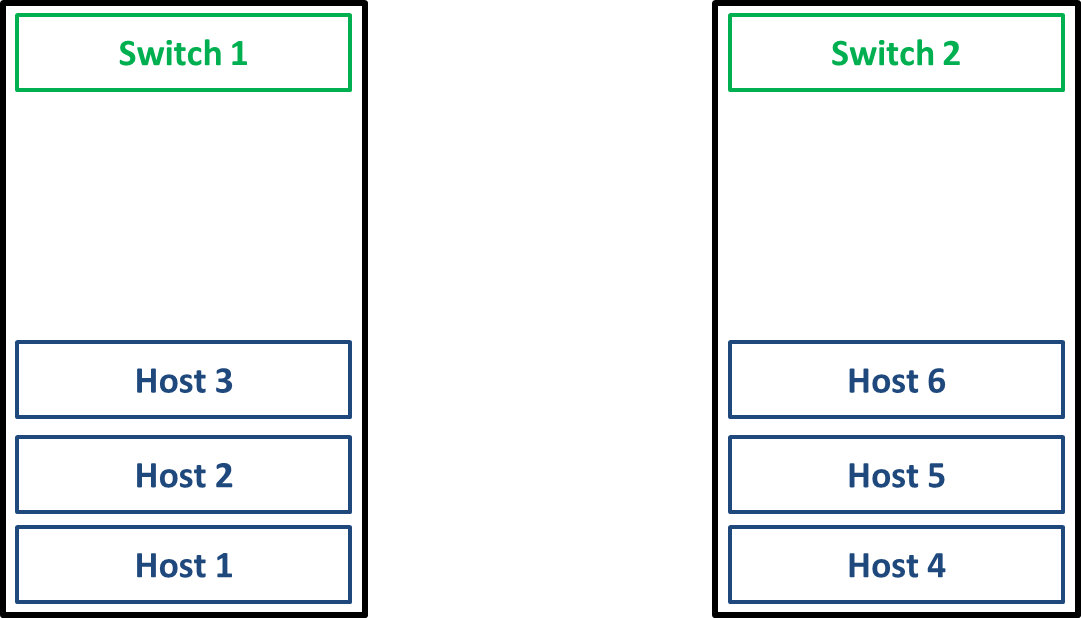
Sounds simple enough, right? Why is that such a big deal? I’ll offer two scenarios in the same cluster set up. Let’s say we have a VMware cluster made up of six hosts. Due to data center space limitations, three of the hosts in the cluster are in one rack, while the other three are in a rack across the aisle. All hosts connect to the top-of-rack switch in their respective rack, and the switches are linked together. Something like this:
(If you don’t like this scenario, think of the “Hosts” in the diagram as “blade servers” and the “racks” as “blade chassis”. That would make the “Switches” a “backplane”.)
Scenario 1: Performance
Let’s say I have a group of VMs for which performance is more important than any other factor. I could create two fault domains, one containing Host 1, Host 2, and Host 3, and the other containing Host 4, Host 5, and Host 6. All mirroring of writes will happen within the domain, meaning that no latency from traffic crossing distance to another switch gets added to the mirroring.
Admittedly, an “across the aisle” distance won’t add much latency, but what if those two racks were at opposite ends of a huge data center? Or in different physical locations as part of a metro stretch cluster? In that case, the fault domain ensures that writes aren’t slowed by having mirroring occur over distance.
Scenario 2: Protection
Now, let’s say I have another group of VMs for which ensuring that every write gets saved is more important than any other factor. I could create three fault domains: one containing Host 1 and Host 4, one containing Host 2 and Host 5, and one containing Host 3 and Host 6. All mirroring of writes will happen within the domain, ensuring that a copy of the write exists in each physically-separate rack before the write is acknowledged to the VM.
In this scenario, data written by my VMs will be protected even in the event I have a power loss to an entire rack (or entire data center in the metro stretch cluster case).
Adaptive Network Compression
When mirroring data to another host, FVP applies inline compression on the data to decrease the overhead and the time to take to copy the data to the other host, thus helping increase performance.
Interestingly, FVP on the target host does not decompress the data, but instead writes it to Flash in its compressed state, getting another performance boost.
What’s New in FVP 2.5?
The update adds three new features:
- DFTM-Z
- Intelligent I/O Profiling
- Role-Based Access Control (RBAC)
DFTM-Z
We’ve already seen above that DFTM is Distributed Fault-Tolerant Memory, so you’re likely wondering what “DFTM-Z” is. It’s DFTM with adaptive compression. Why Z? Because FVP uses the open source LZ4 compression algorithms developed by Google. LZ4 is a very fast, lossless algorithm that uses a fixed compression chunk size of 512KB.
Why compress data in RAM? To get more effective RAM space. Often cost limits the size of the total RAM used in hosts. DFTM-Z allows customers to get more use out of the RAM they have.
What’s adaptive compression? FVP’s DFTM-Z doesn’t blindly compress all data written to RAM. It checks the data first to see if the data set shows good compressibility (some data sets will compress more than others of the same size), and then applies compression only if the data set is a good candidate for it.
Why compression and not deduplication? Two reasons: First, a lower CPU overhead. Second, some workloads (like databases) work better compressed than they do deduplicated.
Won’t this take over all my RAM? DFTM-Z limits the size of the “compressed region” of the RAM assigned to FVP, ensuring that there’s faster, uncompressed RAM space always available. The maximum allowable size of the compressed region is limited by FVP so it’s never more than a set percentage of the assigned RAM.
Intelligent I/O Profiling
This feature allows FVP to have different behavior for different workloads on the same VM. This becomes necessary because while most workloads benefit from the acceleration FVP provides, not all workloads do. In particular, continuous, large, sequential I/O (like the kind produced by Oracle RMAN, some backup software, and anti-virus scans) not only doesn’t really benefit from the Flash used by FVP, it can “pollute” the Flash by filling it with data that will receive no cache hits, thus degrading the performance of FVP acceleration.
I know, your first thought is “Well, just don’t use FVP on VMs with that kind of workload.” Problem is, that’s not enough of a solution, as during the day an Oracle database could run a very random, high-transaction OLTP workload that would benefit immensely from FVP acceleration, and then at midnight run an RMAN backup that wouldn’t and would slow other VMs using FVP.
That’s the problem the I/O profiles seek to fix. A profile provides a way to change the configuration to, for example, have the sequential workload bypass the Flash layer entirely while the RMAN job runs.
In it’s initial release Intelligent I/O Profiles are a manual-only feature. This will work well for planned events (like backups), but won’t let FVP automatically detect a workload change and adjust its configuration on the fly. Future versions of FVP will include more automation of the I/O Profiles.
In order to make the manual processes easier, PernixData is releasing a new set of PowerShell Cmdlets to work with I/O Profiles. These cmdlets will operate only on VM objects (not datastores), and will make it easier for VMware admins to set up automated scripts to trigger I/O Profile changes for scheduled events.
Role-Based Access Control (RBAC)
By adding Role-Based Access Control, PernixData adds more security by offering more control over who can do what. In 2.0, FVP really only has one access mode, and that’s all-access.
In 2.5, FVP has three distinct levels of access. They are:
- Read and Write – the ability to view FVP configurations, usage, and performance charts and the ability to change configurations
- Read-Only – the ability to view FVP configurations, usage, and performance charts, but no ability to change configurations
- No Access – an explicit “deny” role, allowing customers to set up security by default
If you’re familiar with VMware vCenter roles, the equivalent mapping is:

Availability
PernixData’s FVP 2.5 will be GA in early March.

Small correction : LZ4 is not developed by Google.
It is developed by an indepedent, called Yann Collet.
Google equivalent proposition is called snappy.
LZ4 seems to have displaced it within all major applications, being superior in every point.
Pingback: PernixData Announces General Availability of FVP 3.0 | GeekFluent