The company says their name is derived from the Latin word apparare which means “to prepare”. Now, I’ve never had any formal training in Latin, but my own research suggests that apparare is actually a noun that is more accurately translated as “preparations”, so it’s still in the neighborhood they were shooting for. (There are some readers asking themselves right now: “Was that bit of nit-picking really necessary?” To them, I answer, “You haven’t known me very long, have you?”)
Whether you view it as preparing or making preparations, the name is a fitting one. Aparavi’s software offers a solution to make managing long-term retention of data across multiple clouds simple.
In order to explain what Aparavi is, I thought it might be easier to take a step back and explain with it isn’t.
Aparavi is a Software-as-a-Service platform that allows customers to manage the long-term retention of their data both on-site and in the Cloud. It supports S3 and is cloud-agnostic, so customers can use the cloud storage vendor — or vendors — of their choice, and even switch cloud vendors, all while keeping their archive data safe and secure.
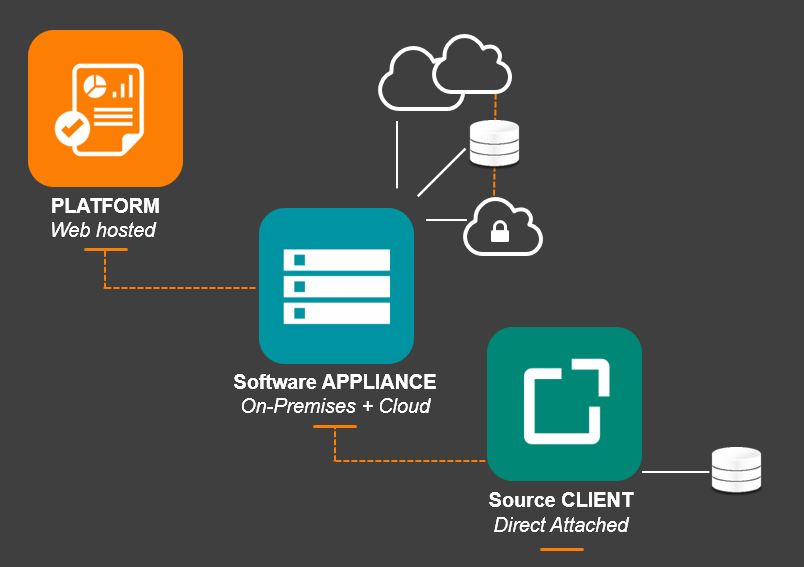
The Aparavi solution is built on a three-tiered architecture as shown in the diagram below.
The tiers are:
The Web-hosted platform – The web portal is where customers configure their data-retention policies. It handles the overall management tasks including monitoring, billing, and provisioning.
The Software appliance – This machine can be run on-site as a physical or virtual server in the customer’s data center or remotely as a virtual machine in the cloud of the customer’s choice. The appliance manages file-based snapshots and archives. The appliance performs in-file data deduplication, and manages byte-level incremental changes to ensure that only new data is moved. The appliance also uses multi-streaming to increase performance.
The Source Client – The client acts as an on-site temporary recovery location, allowing for immediate recovery without affecting the original files. The client also handles all of the encryption for the Aparavi solution (using AES-256) to ensure that the customer’s data is not exposed either in transit or at rest. Interestingly, Aparavi encrypts both data and metadata.
Customers install Aparavi agents on all machines they want (or are required to for compliance reasons) to archive files from. The customer uses the Web Platform to set the data retention policies regarding not only which files should be archived and retained for what period of time, but also where that archived data should be stored.
Upon receiving instructions from the Web Platform, the Appliance uses the Agents to initiate file-based snapshots, encrypts the data with keys from the Client, and then moves the snapshot to the location that the Web Platform’s policy says to.
Example 1: The customer has decided that some of the data they need to retain is more important — or more likely to need rapid recovery — than other data. They contract with two different cloud providers. One provider replicates the storage to a second data center, offering higher availability, the other provider does not. When Aparavi takes snapshots of files meeting the “high-value” criteria, the snaps are written to the highly-available provider. Similarly, snapshots of files in the “lower value” category are written to the other provider. When the customer wants to recover a set of files, they don’t need to know which snapshots are stored with which provider — Aparavi will recover the requested set of files from either or both providers.
Example 2: The customer has contracted with Provider A for cloud storage. At a later date, Provider B offers the customer a better rate for new storage, so the customer also contracts with provider B. The customer simply changes their policies on the Web Platform to instruct Aparavi to write new data to Provider B. When recovering files, if some of the data stored on Provider A and some on Provider B is needed, Aparavi retrieves the data from both providers. If at a later date, the customer decides to migrate off of Provider A entirely, they can set that change via the Web Platform, and Aparavi will migrate the data stored on Provider A to Provider B, and update its indexes accordingly.
Aparavi agents are available for:
Today, Aparavi supports Amazon Simple Storage Service and Google Cloud for cloud storage, and Wasabi, IBM Bluemix, Scality, and Cloudian for on-site storage. Aparavi is building support for Microsoft Azure and OpenStack for Oracle Cloud.
Aparavi pricing is done on a subscription basis and is based upon the amount of source data being protected.
The first Terabtye is always free. (Yes, free.)
A one-year subscription for a customer’s next 3TB of protected data would cost $999 USD.
{kind=link}
{kind=link}